With the market of the chatbots completely booming, it has never been more important to give them a voice and moreover, a human-like one. New technologies in Artificial Intelligence make that possible. In this post we will show you how exactly you can use Google technologies to make a bot speak a certain language: Flemish. As this is a very local language, spoken only by about 7 million people, no big tech company adapts these state-of-the-art methods to it (yet!).
However, we do feel that it can be an appreciated feature for all those native Flemish speakers to have their bot or voice assistant speak their very own language variant, not the generic Dutch version of it. So during our internship at Fourcast we decided to go and try to make what the giants didn’t: a Flemish-speaking bot voice!
This blog post will follow our journey into voice synthesis as we lived it in the past month. We will talk about the different technologies, how we used them on English language first, how we built a Flemish dataset and finally the results (and the problems!) we obtained.
Choosing a model
The first step of our journey consists in finding an open-source text-to-speech model to build onto. There are several text-to-speech technologies out there, but most of them require very complex sets of data in order to produce results. In other words, they need to know the correspondence between words, sounds and phonetic alphabet for each text of the training test.
However, Google has recently developed a new machine learning model: the Tacotron (because they love tacos)!
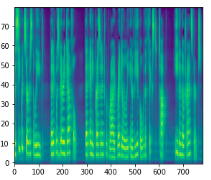
The Tacotron only requires matching sound/text samples in order to learn to speak. Then, from a given text, the model predicts a mel-spectrogram (see picture below) which is an acoustic time-frequency representation of a sound.
From that representation it is possible to generate audio using either an iterative algorithm (Griffin-Lim) or another neural network model called Wavenet. The latter produces very good results that can in the best case be compared to human voice. But it also has to be trained using audio samples.
“Generative adversarial network or variational auto-encoder” Example:
In short: text → Tacotron → mel‑spectrogram → vocoder → audio.
Model testing in English first
To be sure that the models would work for our purpose and would produce the expected results, we first tested them with an English dataset. This dataset was specifically designed for the purpose of voice synthesis and is named LJSpeech. As we had to make the models run and also bridge some of them together, we tried to automate those parts by using as much scripting as possible.
The results on the English version were promising with only a few hours of training of the models, whereas normally a few days are expected to get the best results. Moreover, the inference time – the time needed to produced the voice from the text – was very fast: ~1.2 seconds max for an average sentence. We were then confident that the technology would work for Flemish too, at least with the right dataset, and moved on to the next step.
Monitoring during training
To avoid flying blind, we tracked training remotely with TensorBoard and focused on two indicators:
- Training/validation loss: drops quickly at first, then plateaus when the model converges.
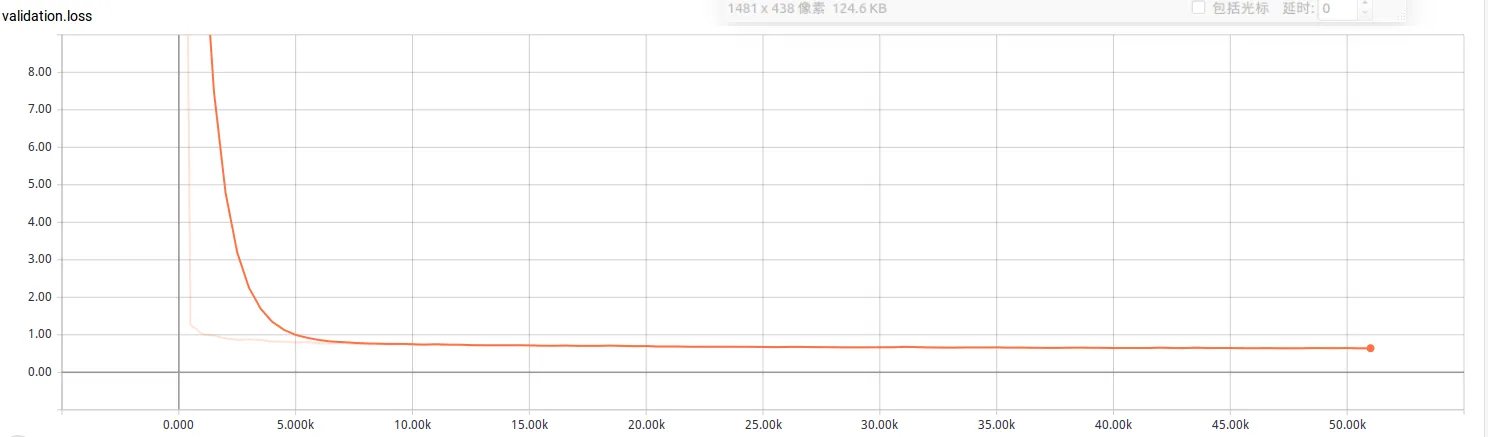
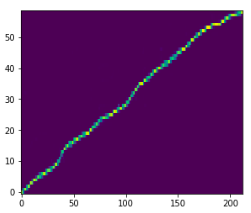
- Alignment graph: a thin, straight diagonal usually predicts intelligible audio; a thick or erratic pattern correlates with poor speech.
Ingesting the data (Flemish)
What we needed:
- ~10+ hours of short clips (1–15 s)
- High‑quality audio, single speaker, neutral tone
- Accurate transcriptions paired to each clip
We looked into existing corpora (e.g., the Gesproken Corpus Nederlands), but quality constraints made them unsuitable for Tacotron. We turned to audiobooks for their clean, single‑speaker recordings.
The workflow involved:
- Splitting book text into sentence‑level samples
- Producing a manifest mapping text samples to filenames
- Cutting audio by timestamps to create matching clips
Initially, timestamping was fully manual (painfully slow). We then modified a lightweight audio player so pressing Return would log timestamps on the fly. The whole team pitched in to flag mismatches and timing errors, which we corrected by adjusting timestamps and regenerating clips.
Automation for the win
That small tooling tweak (keystroke‑driven timestamp capture) sped up dataset creation dramatically. It wasn’t perfect — occasional early/late cuts or transcription slips still happened — but it made the process feasible in our timeframe.
The end of the road: let’s train!
We trained our models on the Google Cloud Platform twice: once before correcting the dataset and once after. With the corrected dataset, we obtained understandable Flemish after only 10 hours of training of our models!
Unfortunately, the quality of the sound is pretty bad, and doesn’t improve with a longer training nor with a wavenet synthesizer. Here you can listen to the results with and without wavenet:
“Ik woon in een groot huis en ik zou graag frietjes eten.” was our example sentence you can hear for both with and without Wavenet:
Griffin-Lim
Wavenet
How to improve?
- Prefer uncompressed or lossless audio (MP3 compression hurts spectrogram quality)
- Scale the dataset beyond the bare minimum (~10 h)
- Use studio‑grade, professional narration (closer to LJSpeech conditions)
Conclusion
We finally obtained a result of which we are pretty proud: our text-to-speech can say any Flemish sentence properly! Although the result quality is not sufficient to be used in a real-world application, this is already a good start. We also came up with some ideas to improve these results, based on our experience with the Tacotron model.
If we were to give a single advice, it would be this one: take the time to build a proper dataset, even if it requires 60% of the time spent in the project. Because, as is often the case in machine learning, it is the data and not the learning model that allows you to create powerful models. Before starting this project, we were wondering: “why didn’t Google, with their powerful tacotron, release voice synthesis in every language?”. Now we know the answer. They need excellent quality datasets to achieve those remarkable results and it takes a lot of time and money to create this. That’s why minor languages and dialects are not well represented yet in the Google Speech API’s.
Our internship already comes to an end, but we hope our work will gives Fourcast a small head start in building the first Flemish text-to-speech engine!
—
Our original post can be found on https://www.devoteam.com/be/expert-view/a-journey-into-voice-synthesis-or-how-we-tried-to-make-a-bot-speak-flemish/